create table team
(
team_id bigint,
team_name varchar(100),
created_at timestamp with time zone
);
데이터 세팅
INSERT INTO team (team_id, team_name, created_at)
SELECT i,
'Team ' || i,
CURRENT_TIMESTAMP - INTERVAL '1 day' * (i % 365)
FROM generate_series(1, 10000) AS i;
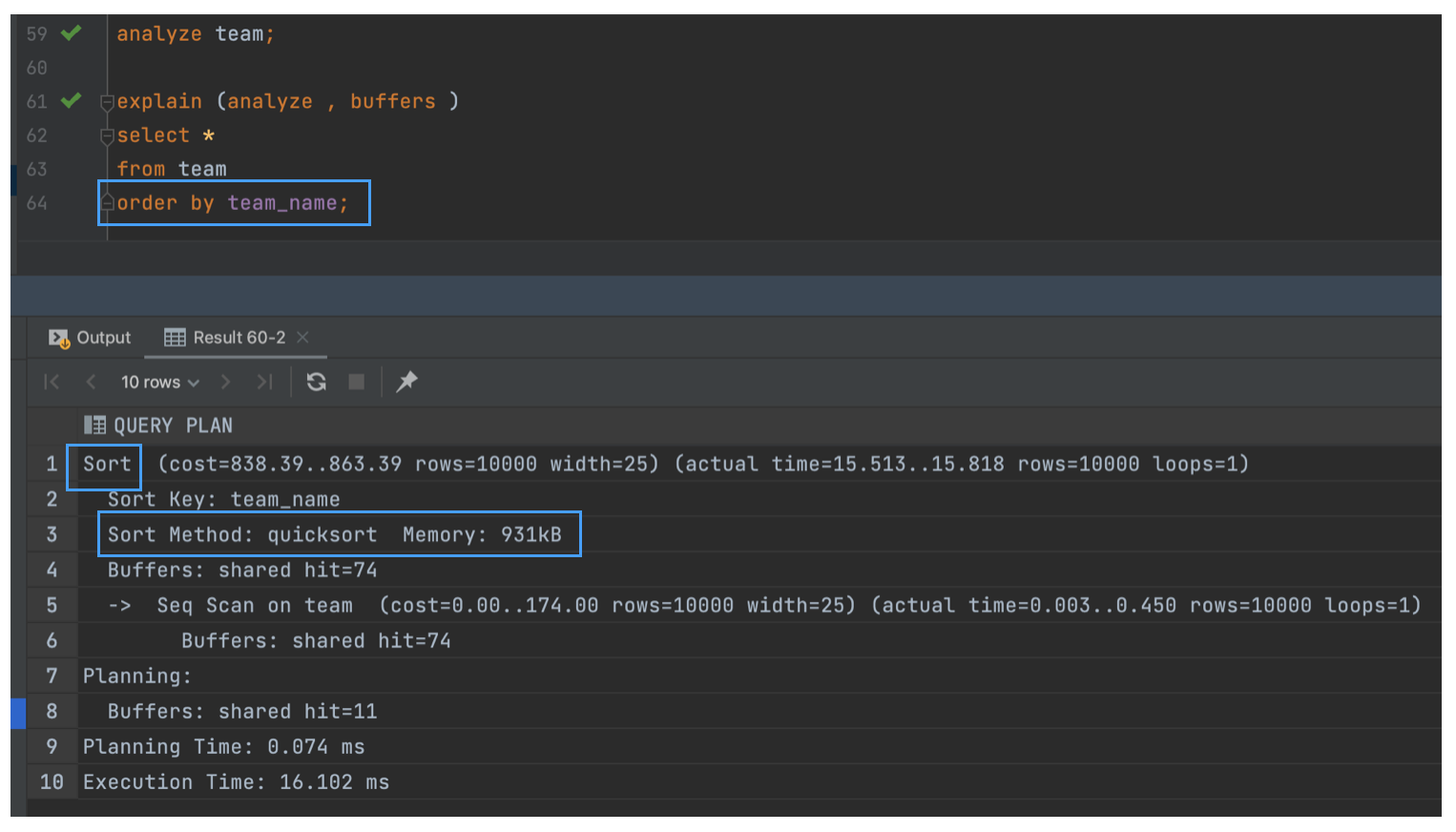
Sort
ORDER BY 를 처리할 때 주로 발생하며, 이외에도 DISTINCT, GROUP BY, UNION, 그리고 병합 조인(merge joins)과 같은 상황에서 발생한다.
상당한 시작 시간(startup time)이 필요할 수 있다.
정렬이 work_mem 설정 내에서 수행될 수 있다면, 빠른 퀵소트(quicksort) 알고리즘이 사용됩니다.
정렬이 메모리 용량을 초과할 경우, 디스크로 이동하여 임시 파일을 사용하는데, 이는 비용이 많이 드는 작업이 될 수 있다.
Sort Method 부분을 보면 quicksort 방식이 사용되었으며, 이는 메모리 내에서 정렬이 이루어졌음을 의미한다.
이번에는 데이터양을 좀 더 늘려보자. 1만 -> 100만 건으로 늘렸다.
INSERT INTO team (team_id, team_name, created_at)
SELECT
i,
'Team ' || i,
CURRENT_TIMESTAMP - INTERVAL '1 day' * (i % 365)
FROM
generate_series(1, 1000000) AS i;
이제 다시 실행계획을 살펴보자
Sort Method 가 External Merge 방식으로 처리된 것을 확인할 수 있다. 이는 정렬작업을 work_mem에서 처리하기에 데이터양이 너무 커서 디스크에서 진행했음을 의미한다.
또한, 41520kb 만큼 메모리(work_mem)를 초과하여 필요한 추가 저장 공간을 디스크에서 확보했음을 의미한다.
따라서, External Merge 방식으로 정렬작업이 이루어지고 있다면, 인덱스를 통해서 Sort 작업을 처리하는 방법을 고려해봐야 한다.
위에서 볼 수 있듯이, 인덱스를 사용하면 Sort 연산을 대신처리할 수 있고, 데이터가 많은 경우 훨씬 좋은 성능을 볼 수 있다.
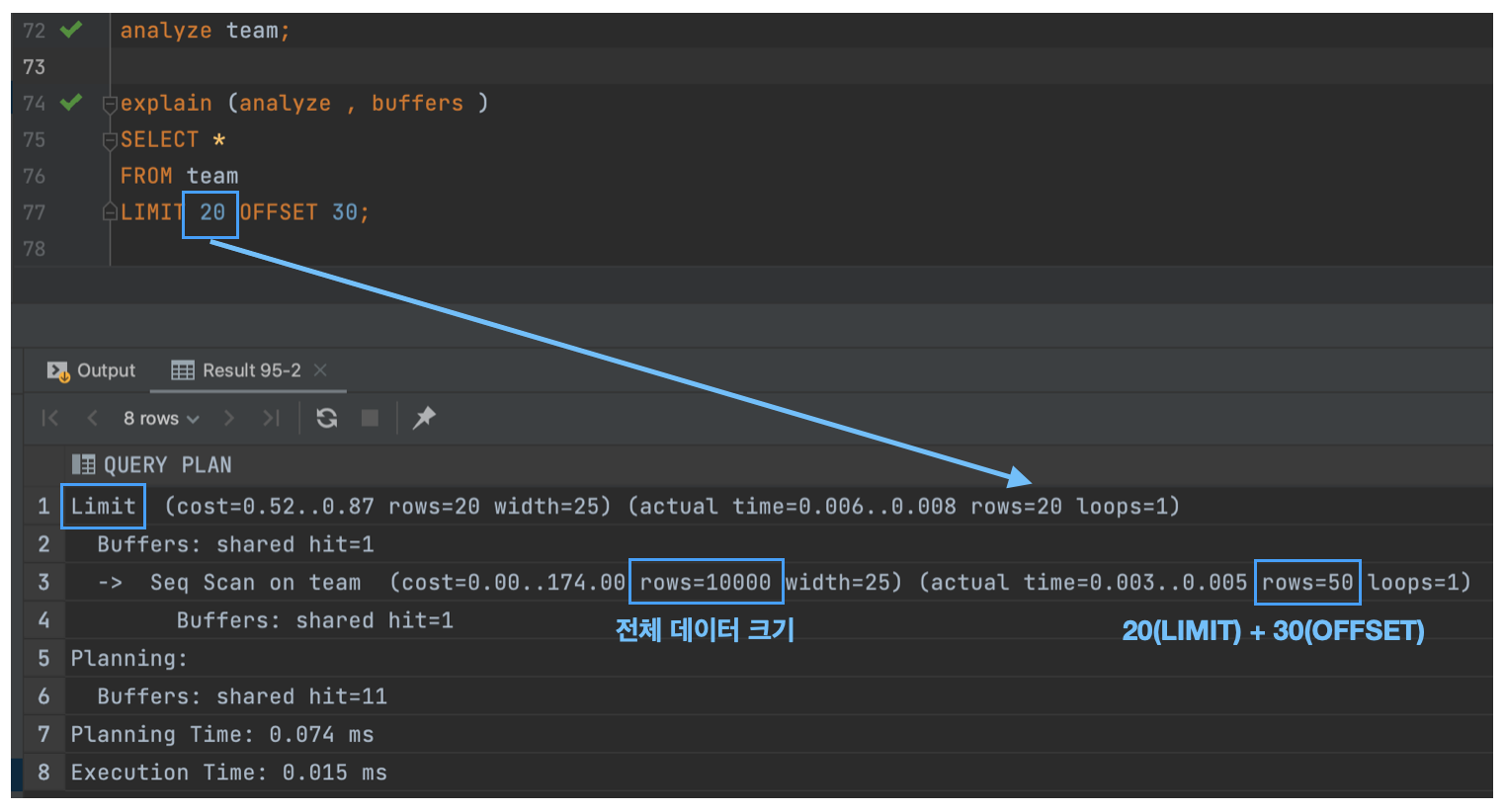
Limit
LIMIT과 OFFSET를 처리할 때 주로 발생한다.
그렇기 때문에 보통 패이징을 처리하는 쿼리의 실행계획에 등장한다.
이제 실행계획을 살펴보자.
먼저, 주목할 점은 (actual time=0.003..0.005 rows=50 loops=1) 이 부분이다.
나는 처음에 rows가 20일 거라 생각했다. 그 이유는 31번째부터 50번째만 읽어올 거라 생각했다.
하지만, 50개의 데이터를 전부 읽어오고 그중 앞에 30개를 건너뛰고 20개만 반환해 주는 형태로 실행된다. 그렇기 때문에 rows는 50이다.
그렇다면, 페이징 처리에 있어서 OFFSET 값이 커질수록 읽어야 되는 데이터가 많아지기 때문에 실행시간은 증가한다는 사실을 알 수 있다.
다음은 (cost=0.00..174.00 rows=10000 width=25) 이 부분이다.
옵티마이저는 Seq Scan 연산의 예상 행 수를 계산할 때 LIMIT과 OFFSET을 고려하지 않는다. 따라서 전체 데이터 크기인 10000을 반환한다.